1
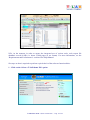
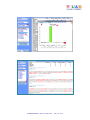
Cluster Analysis, which requires a previous Correspondence Analysis and can be carried out using various techniques, allows us to detect and explore groups of analysis units which have two complementary features: high internal (within cluster) homogeneity and high external (between cluster) heterogeneity. T-LAB Plus 2019 - Quick Introduction - Pag. 20 of 29