1
CHAPTER 3. BUILDING GROUPWARE APPLICATIONS
79
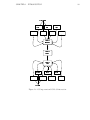
Formally, an application that uses a room is represented as
AP P LICAT ION = {R, C1 , C2 , . . . , CN }
where R is the room application and C1 through CN are parts of the client applications. Each client communicates to the room, and the room communicates to each
client.
A room-based application defines one message type in addition to the standard
THYME messages. This message, the RoomRegistrationMessage, is shown Definition 23. A client sends the RoomRegistrationMessage to the room upon registering
and unregistering from the room. The room rebroadcasts the RoomRegistrationMessage to currently registered clients.
Definition 23 The RoomRegistrationMessage is defined as:
RoomRegistrationMessage = {{CLIENT −DAT A}, REGIST RAT ION −ACT ION}
REGIST RAT ION -ACT ION is chosen from a set {REGIST ER-CLIENT,
UNREGIST ER-CLIENT, CLIENT -HAS-REGIST ERED,
CLIENT -HAS-UNREGIST ERED}.
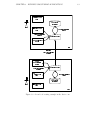
Each room-based application defines their own set of messages to communicate
between clients. The room component is implemented or parameterized to respond
to those messages and selectively pass them to clients.
WYSIWIS groupware that is not replicated exactly is susceptible to externalities
[BSSS01]. An externality arises when the information or presentation accessible to
one party in a collaboration is different than that of another party. The THYME
groupware components presented here do not explicitly address externalities in their
development, but potential externalities are discussed in the component descriptions
below.