1
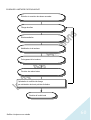
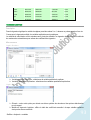
Courbe d'apprentissage Erreur moyenne 0,3 0,25 0,2 Erreur sur l’échantillon test 0,15 0,1 Erreur sur l’échantillon d’apprentissage 0,05 0 52 10 15 20 26 31 36 41 46 52 57 62 67 72 78 83 88 93 98 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 Itérations La phase d’apprentissage et la phase de test La preuve d’un bon résultat Contrairement à la régression multiple, il n’est pas possible de faire un test de significativité du modèle. Une solution consiste à diviser aléatoirement l’échantillon initial en deux sous-échantillons. On estime le modèle sur l’un des souséchantillons, c’est la phase d’apprentissage. L’erreur moyenne doit être la plus petite possible. La deuxième phase consiste à tester le modèle sur l’autre sous-échantillon. Sur cet échantillon, on connaît la valeur de la variable étudiée. Si la valeur estimée n’est pas trop différente de la valeur observée, le modèle est probablement opérationnel. On pourra ensuite présenter au modèle des observations ou individus dont on ne connaît pas la valeur de la variable étudiée. Il est intéressant de faire d’abord une analyse statistique classique et ensuite une analyse neuronale. Cette première analyse donne un point de comparaison intéressant. Nombre de neurones dans la couche cachée : L’équivalent des facteurs Le nombre de neurones de la couche cachée correspond approximativement au nombre de facteurs en analyse factorielle. On introduit dans la couche cachée un nombre inférieur de neurones. En analyse en composantes neuronales, les neurones de la couche cachée jouent un rôle de compression des données ou de réduction du bruit. Si on définit un trop grand nombre de neurones dans la couche cachée en régression ou en analyse discriminante, le modèle risque d’apprendre ‘par cœur’ les données présentées en entrée et ne saura pas généraliser sur un jeu de données inconnu. Une règle approximative consiste à prendre la racine carrée du nombre de neurones en entrée. Mais il faut également prendre en compte la manière dont les données ont été codées au départ. Nature des données en entrée Il est possible a priori de soumettre à un réseau de neurones des données nominales ou quantitatives. L’expérience montre qu’une variable nominale transformée en plusieurs variables Oui/Non (ou en d’autres termes en variables binaires disjonctives) donne de meilleurs résultats. Il est dans ce cas conseillé de transformer les variables numériques en classes. Les variables numériques en entrée qui ont une distribution très grande (supérieure à plus ou moins 3 écart-types par rapport à la moyenne) donnent de moins bons résultats. Dans ce cas StatBox borne les données à plus ou moins 3 écart-types en entrée pendant la phase d’apprentissage. D’autre part pour éviter l’effet des unités de mesure, StatBox réduit l’amplitude des données à l’intervalle 0 et 1. L’amplitude initiale est ensuite reconstituée pour les données en sortie. La régression neuronale Les principes La régression neuronale permet d’établir un lien entre une variable numérique et plusieurs autres variables numériques ou non. Elle est comparable à la régression linéaire multiple. On utilise l’algorithme de rétropropagation StatBox Analyse à n variables 103