1
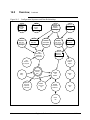
8.8.4 Example Figure 8-5 Retrieving Events for a PRIMMOD Group, Continued In Figure 8-5, events were retrieved for points with DIST841 or FLAG1 in their PRIMMOD parameter in units 01 and 97. Example of PRIMMOD Event History 33458 33459 174 Engineer’s Reference Manual 06/04