1
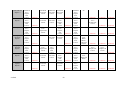
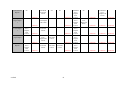
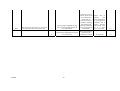
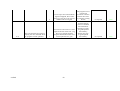
The following describe all the 'could have' techniques. Techniques 5.7 The system shall display the most common paths taken through the website in two dimensional graphical forms overlaid onto the website structure. The following topics describe all the 'could have' functional requirements of the new tool. Y Y 5.8 The system shall operate through a Graphical User interface. WANT TO HAVE BUT NOT THIS TIME Y Y Y Y Functional The following topics describe all the 'want to have but not this time around' techniques. Techniques 5.9 The following topics describe the general requirements of the software, including the non functional requirements. NonFunctional scs2htd The system shall display the most common paths taken through the website in three dimensional graphical forms overlaid onto the website structure. GENERAL 6.0 The system shall inform the user what the current operation is doing so the user does not loose interest and is not confused. Y Y 6.1 The system should be easy to navigate and allow the user to exit or go back at any point. Y Y 6.2 The system should give clear prompts when it is awaiting input. Y Y 6.3 The generation of the reports should take no longer than 10 minutes. Y Y 113