1
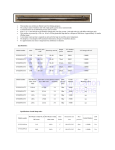
37 Normalization of data is the process of analyzing the relation schemas based on their primary keys in order to minimize the redundancy and minimize the insertion, deletion, and update anomalies. In other words, one can think of this process of the filtering, because it will make the design have better quality. If our relation is not normalized then it might contain redundant data storage, and once our database has been fully developed, it will not organize the data in the most efficient way. Normalization plays an important role that can determine the performance of our database. The types of normalization forms that exist are first normal form (1NF), second normal form (2NF), third normal form (3NF), and Boyce-Codd Normal Form (BCNF) all these forms are described below. 1NF- Also known as first normal form, which is also known as the basic relational model. This form doesn’t allow multivalued attributes, composite attributes, and their combinations. It also states that the domain of an attribute must include only atomic values and that the value in any attribute in a tuple must be a single value from the domain of that attribute. If there are any attributes that are multivalued, or any nested relations then we will form new relations for them. 1NF also disallows relations within relations or relations as attribute values within tuples. It will only permit single atomic values. 2NF- (Second Normal Form) is based on the concept of full functional dependency. Any relation schema R is said to be in 2NF if every non-prime attribute A in R is fully functionally dependent on the primary key of R. In order to normalize to this form we will set up a new relation for each partial key with its dependent attributes. However, we