1
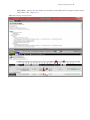
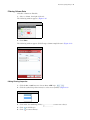
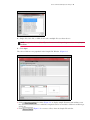
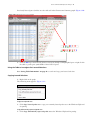
2 Alternative Splicing Analysis Setting Up an Analysis Using Alt Splice CHP Files 1. At the main TAC window, click Alternate Splicing Analysis. (Figure 2.1) Figure 2.1 Main TAC window The New Analysis window appears. (Figure 2.2) Figure 2.2 New Analysis window 2. Click Import Data. The following window appears. (Figure 2.3) It displays the data path you set up earlier and its files. NOTE: The first time you launch TAC, it asks you to define a path to store your library and annotation files. For your convenience, TAC retains this path information. Affymetrix recommends you use the Expression Console library path you already configured.