1
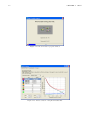
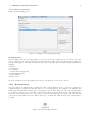
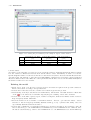
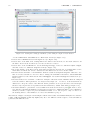
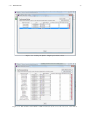
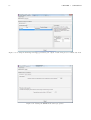
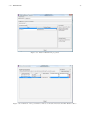
6.1. WORKLOAD ANALYSIS 137 Figure 6.31: Clustering algorithm used and variables selected that will be considered in the analysis. Figure 6.32: Clustering progress panel • the maximum number of iterations to perform in order to find the optimal partition. The initial subdivision into k clusters is iteratively improved by shifting, based on the selected criterion (in this case the Euclidean distance), the elements of a cluster to another and computing after each assignment the new center of mass of the clusters. The optimum configuration is obtained when points can no longer be reassigned. The selected value is an upper limit of the number of interactions for each partition. Experiences suggest the value of 4 interactions as a reasonable choice: the results are obtained in a short time and are enough accurate. To obtain more accurate results higher values should be used, this involves a higher computation time • the transformation type to apply to selected variables (if needed). Transformations of the values are applied before the execution of the algorithm and at the end of the execution the results can be transformed back to their original values. The transformation of the values is often required since the variables are usually expressed in different units and their ranges are very different. Since the algorithm uses the Euclidean distance function as comparison metric to determine if an observation belongs to a cluster, the results could be not reliable if the values differ of one or more order of magnitude. Figure 6.33: Parameters of the clustering algorithm k-Means